

Fujitsu desarrolla tecnología de reconstrucción generativa de IA para modelos de IA optimizados y energéticamente eficientes basados en Takane LLM
Logrando la tasa de retención de precisión más alta del mundo, del 89 %, y una velocidad de inferencia tres veces más rápida con una reducción del consumo de memoria de cuantificación de 1 bit del 94 %.
Fujitsu ha anunciado el desarrollo de una nueva tecnología de reconstrucción para IA generativa. Esta tecnología, que se posiciona como un componente central del servicio Fujitsu Kozuchi AI, reforzará el Fujitsu Takane LLM al permitir la creación de modelos de IA ligeros y energéticamente eficientes.
La nueva tecnología de reconstrucción de Fujitsu se basa en dos avances fundamentales:
- Cuantificación: una técnica que comprime significativamente la información almacenada en las conexiones entre neuronas que conforman la base del “proceso de pensamiento” de un modelo de IA.
- Destilación de IA especializada: un método pionero a nivel mundial (1) que logra de forma simultánea aligerar el modelo y alcanzar una precisión superior a la del modelo original.
-
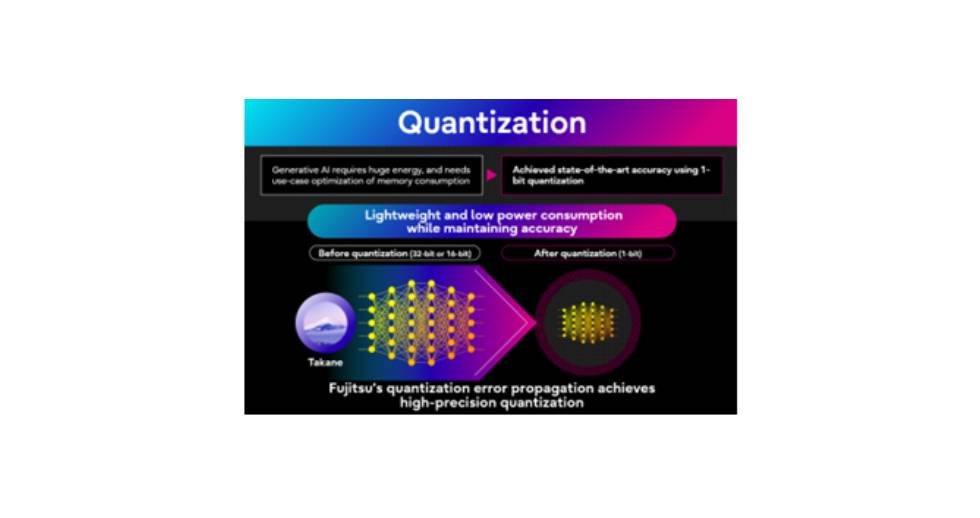
La aplicación de la tecnología de cuantificación de 1 bit a Takane ha permitido una reducción del 94% en el consumo de memoria. Este avance ha alcanzado la tasa de retención de precisión más alta del mundo, del 89% (2) en comparación con el modelo sin cuantificar, junto con un incremento de 3 veces en la velocidad de inferencia. Este resultado supera ampliamente la tasa de retención de precisión, inferior al 20%, que suelen lograr métodos convencionales como GPTQ. Este hito permite que grandes modelos de IA generativa, que antes requerían cuatro GPU de alto rendimiento, puedan ejecutarse de forma eficiente en una sola GPU de gama baja.
Esta capacidad sin precedentes permitirá el despliegue de IA agente en dispositivos periféricos, como smartphones y maquinaria industrial, lo que se traducirá en mejor respuesta en tiempo real, mayor seguridad de los datos y una drástica reducción del consumo energético de las operaciones de IA, contribuyendo a una sociedad de IA sostenible.
Fujitsu tiene previsto ofrecer a sus clientes de todo el mundo entornos de prueba de Takane con la tecnología de cuantificación aplicada a partir de la segunda mitad del ejercicio fiscal 2025. Además, Fujitsu lanzará progresivamente modelos de Cohere Command A con pesos abiertos, cuantificados con esta tecnología y disponibles en Hugging Face (3) a partir de hoy.
En adelante, Fujitsu continuará avanzando en investigación y desarrollo para mejorar significativamente las capacidades de la IA generativa garantizando su fiabilidad, con el objetivo de resolver desafíos más complejos para clientes y sociedad, y abrir nuevas posibilidades de uso de la IA generativa.
Detalles de la tecnología
Muchas tareas realizadas por agentes de IA requieren solo una fracción de las capacidades generales de un LLM. La nueva tecnología de reconstrucción de IA generativa está inspirada en la capacidad del cerebro humano de reorganizarse y especializarse en habilidades concretas en respuesta al aprendizaje, la experiencia y los cambios del entorno. Esta tecnología extrae de manera eficiente solo el conocimiento necesario para tareas específicas a partir de un modelo general, creando un modelo especializado, ligero, eficiente y fiable.
Se basa en dos tecnologías principales:
1. Cuantificación para optimizar el “pensamiento” de la IA y reducir el consumo energético:
- Compresión de parámetros: reduce el tamaño del modelo y el consumo de energía, acelerando el rendimiento.
- Solución al error de cuantificación: Fujitsu ha desarrollado un nuevo algoritmo de propagación de error de cuantificación que evita la acumulación exponencial de errores en redes neuronales profundas.
- Cuantificación de 1 bit: lograda mediante un algoritmo propio de optimización líder mundial para problemas a gran escala.
2. Destilación especializada para condensar conocimiento y mejorar la precisión:
- Optimización inspirada en el cerebro: reconfiguración estructural del modelo imitando procesos de refuerzo del conocimiento y organización de la memoria.
- Generación y selección de modelos:
- Eliminación de conocimiento innecesario y adición de bloques de transformer.
- Generación de múltiples modelos candidatos.
- Selección del modelo óptimo mediante Neural Architecture Search (NAS) adaptado a los requisitos de recursos GPU, velocidad y precisión.
- Destilación del conocimiento: transferencia de conocimiento desde modelos maestros (como Takane) hacia el modelo seleccionado.
- Más allá de la compresión: mejora de la precisión en tareas especializadas, superando al modelo generativo original.
Resultados demostrados:
Predicción en negociaciones comerciales:
- Tarea de preguntas y respuestas con datos de CRM de Fujitsu.
- 11 veces más velocidad de inferencia.
- Mejora del 43% en precisión.
- El modelo alumno (1/100 del tamaño en parámetros) superó al modelo maestro.
- Reducción del 70% en memoria GPU y costes operativos.
- Reconocimiento de imágenes:
- Mejora del 10% en la detección de objetos no vistos (4) respecto a técnicas de destilación existentes.
- Logro significativo: más de tres veces de mejora en dos años en este campo.
Planes futuros
Fujitsu seguirá potenciando Takane con esta tecnología para impulsar la transformación empresarial de sus clientes. Entre los próximos pasos se incluyen modelos ligeros y especializados de IA agente derivados de Takane en sectores como finanzas, manufactura, salud y retail.
Las futuras mejoras tecnológicas aspiran a una reducción de hasta 1/1000 en el tamaño de memoria de los modelos sin sacrificar precisión, permitiendo una IA generativa ubicua de alta precisión y alta velocidad. A largo plazo, los modelos especializados de Takane evolucionarán hacia arquitecturas avanzadas de IA agente, con una mayor comprensión del mundo y capacidad para resolver problemas complejos de manera autónoma.
La nueva tecnología de reconstrucción de Fujitsu se basa en dos avances fundamentales:
- Cuantificación: una técnica que comprime significativamente la información almacenada en las conexiones entre neuronas que conforman la base del “proceso de pensamiento” de un modelo de IA.
- Destilación de IA especializada: un método pionero a nivel mundial (1) que logra de forma simultánea aligerar el modelo y alcanzar una precisión superior a la del modelo original.
La aplicación de la tecnología de cuantificación de 1 bit a Takane ha permitido una reducción del 94% en el consumo de memoria. Este avance ha alcanzado la tasa de retención de precisión más alta del mundo, del 89% (2) en comparación con el modelo sin cuantificar, junto con un incremento de 3 veces en la velocidad de inferencia. Este resultado supera ampliamente la tasa de retención de precisión, inferior al 20%, que suelen lograr métodos convencionales como GPTQ. Este hito permite que grandes modelos de IA generativa, que antes requerían cuatro GPU de alto rendimiento, puedan ejecutarse de forma eficiente en una sola GPU de gama baja.
Esta capacidad sin precedentes permitirá el despliegue de IA agente en dispositivos periféricos, como smartphones y maquinaria industrial, lo que se traducirá en mejor respuesta en tiempo real, mayor seguridad de los datos y una drástica reducción del consumo energético de las operaciones de IA, contribuyendo a una sociedad de IA sostenible.
Fujitsu tiene previsto ofrecer a sus clientes de todo el mundo entornos de prueba de Takane con la tecnología de cuantificación aplicada a partir de la segunda mitad del ejercicio fiscal 2025. Además, Fujitsu lanzará progresivamente modelos de Cohere Command A con pesos abiertos, cuantificados con esta tecnología y disponibles en Hugging Face (3) a partir de hoy.
En adelante, Fujitsu continuará avanzando en investigación y desarrollo para mejorar significativamente las capacidades de la IA generativa garantizando su fiabilidad, con el objetivo de resolver desafíos más complejos para clientes y sociedad, y abrir nuevas posibilidades de uso de la IA generativa.
Detalles de la tecnología
Muchas tareas realizadas por agentes de IA requieren solo una fracción de las capacidades generales de un LLM. La nueva tecnología de reconstrucción de IA generativa está inspirada en la capacidad del cerebro humano de reorganizarse y especializarse en habilidades concretas en respuesta al aprendizaje, la experiencia y los cambios del entorno. Esta tecnología extrae de manera eficiente solo el conocimiento necesario para tareas específicas a partir de un modelo general, creando un modelo especializado, ligero, eficiente y fiable.
Se basa en dos tecnologías principales:
1. Cuantificación para optimizar el “pensamiento” de la IA y reducir el consumo energético:
- Compresión de parámetros: reduce el tamaño del modelo y el consumo de energía, acelerando el rendimiento.
- Solución al error de cuantificación: Fujitsu ha desarrollado un nuevo algoritmo de propagación de error de cuantificación que evita la acumulación exponencial de errores en redes neuronales profundas.
- Cuantificación de 1 bit: lograda mediante un algoritmo propio de optimización líder mundial para problemas a gran escala.
2. Destilación especializada para condensar conocimiento y mejorar la precisión:
- Optimización inspirada en el cerebro: reconfiguración estructural del modelo imitando procesos de refuerzo del conocimiento y organización de la memoria.
- Generación y selección de modelos:
- Eliminación de conocimiento innecesario y adición de bloques de transformer.
- Generación de múltiples modelos candidatos.
- Selección del modelo óptimo mediante Neural Architecture Search (NAS) adaptado a los requisitos de recursos GPU, velocidad y precisión.
- Destilación del conocimiento: transferencia de conocimiento desde modelos maestros (como Takane) hacia el modelo seleccionado.
- Más allá de la compresión: mejora de la precisión en tareas especializadas, superando al modelo generativo original.
Resultados demostrados:
Predicción en negociaciones comerciales:
- Tarea de preguntas y respuestas con datos de CRM de Fujitsu.
- 11 veces más velocidad de inferencia.
- Mejora del 43% en precisión.
- El modelo alumno (1/100 del tamaño en parámetros) superó al modelo maestro.
- Reducción del 70% en memoria GPU y costes operativos.
- Reconocimiento de imágenes:
- Mejora del 10% en la detección de objetos no vistos (4) respecto a técnicas de destilación existentes.
- Logro significativo: más de tres veces de mejora en dos años en este campo.
Planes futuros
Fujitsu seguirá potenciando Takane con esta tecnología para impulsar la transformación empresarial de sus clientes. Entre los próximos pasos se incluyen modelos ligeros y especializados de IA agente derivados de Takane en sectores como finanzas, manufactura, salud y retail.
Las futuras mejoras tecnológicas aspiran a una reducción de hasta 1/1000 en el tamaño de memoria de los modelos sin sacrificar precisión, permitiendo una IA generativa ubicua de alta precisión y alta velocidad. A largo plazo, los modelos especializados de Takane evolucionarán hacia arquitecturas avanzadas de IA agente, con una mayor comprensión del mundo y capacidad para resolver problemas complejos de manera autónoma.

Normas de participación
Esta es la opinión de los lectores, no la de este medio.
Nos reservamos el derecho a eliminar los comentarios inapropiados.
La participación implica que ha leído y acepta las Normas de Participación y Política de Privacidad
Normas de Participación
Política de privacidad
Por seguridad guardamos tu IP
216.73.216.42